Companies today enjoy a great set of tools for analyzing structured data. However, the most essential and actionable insights are precisely where they are hardest to discover: in the unstructured data such as call transcripts, customer support cases, product reviews, or financial documents. Since this data is unstructured, however, it often goes unanalyzed. Sturdy Statistics has the unique ability to automatically convert unstructured data into a structured format. This format allows you to process unstructured documents if they were tabular, using the tools you’re already familiar with.
To see how this automatic structuring works, let’s see how it works with a dataset of financial documents. We uploaded earnings calls from a sample of large tech companies (AAPL, AMZN, GOOG, META, MSFT, and NVDA) from the past four years. The Sturdy Statistics model then automatically inferred the important topics in the dataset, and categorized each document according to its thematic content. We show a small portion of the resulting data below:
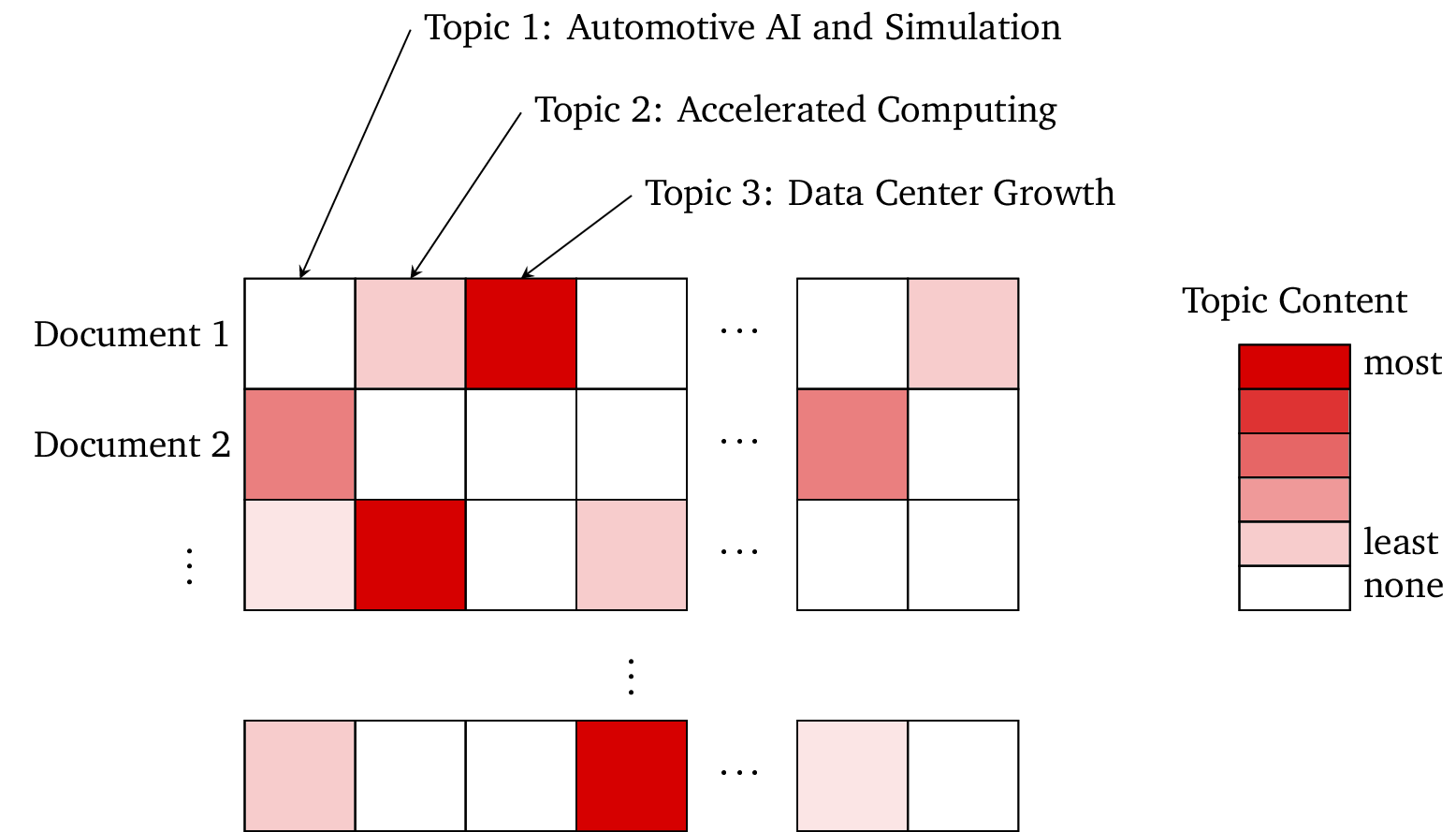
You can see that we have imputed meaningful topics with easily-interpretable names, and that each document can be easily understood according to its thematic content. Unlike LLM embeddings, each column in this representation corresponds to a meaningful, immediately interpretable concept, and most of the columns are zero. These properties greatly enhance the utility of our representation: because you can understand our features, you can use them directly, without needing to train a downstream machine-learning model. (Of course, our human-readable features also make excellent inputs to machine learning models if that is your goal.)
However, we don’t only structure documents in this way. In the above example, we can see that Document 1 is primarily about Data Center Growth, but that it also touches on Accelerated Computing. We can inspect this document paragraph-by-paragraph and see where it mentions each of these topics. While each document typically covers several (and can contain many) topics, a paragraph typically only has one or two topics:
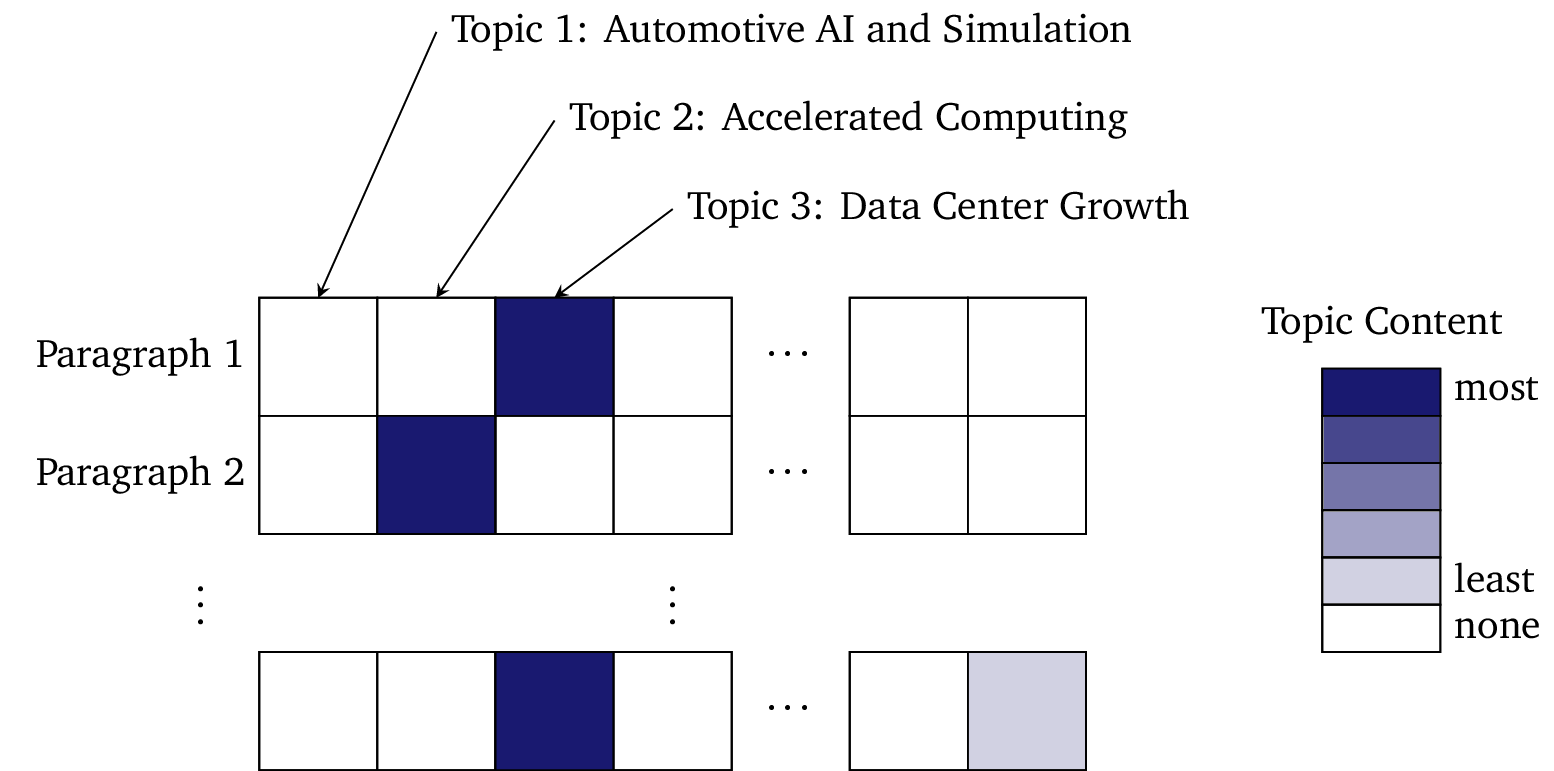
Since paragraphs are so sparse — with each containing just one or two topics — they behave extremely well for semantic search with our technology. (See a description of our search API here.)
Because of this close mapping from paragraphs to topics, we can easily retrieve example paragraphs for any topic. For example, the top paragraph containing the topics Data Center Growth and Accelerated Computing in the dataset is as follows (from Nvidia’s 2023Q2 earnings call):
Colette Kress: Thanks, Simona. Q1 revenue was $7.19 billion, up 19% sequentially and down 13% year-on-year. Strong sequential growth was driven by record data center revenue, with our gaming and professional visualization platforms emerging from channel inventory corrections. Starting with data center, record revenue of $4.28 billion was up 18% sequentially and up 14% year-on-year, on strong growth by accelerated computing platform worldwide. Generative AI is driving exponential growth in compute requirements and a fast transition to NVIDIA accelerated computing, which is the most versatile, most energy-efficient, and the lowest TCO approach to train and deploy AI.
Where we have highlighted the words most emblematic of these topics.
In similar fashion, we can split a paragraph into sentences and inspect each of their topics. Or, we can go in the other direction and look at sections, chapters, or even groups of documents. We can impute this thematic structure at any scale in your data. See the sections on our search API or our data lake for some examples of what you can do with this structuring.